Retrospective
Trimester 2 Retrospective
Personal Contribution Analytics : Shriya
This document summarizes measurable development contributions made throughout the project.
- Commits: 65 commits to Spring and Pages in the 2 months
- Pull Requests: 9 for Spring and Pages
-
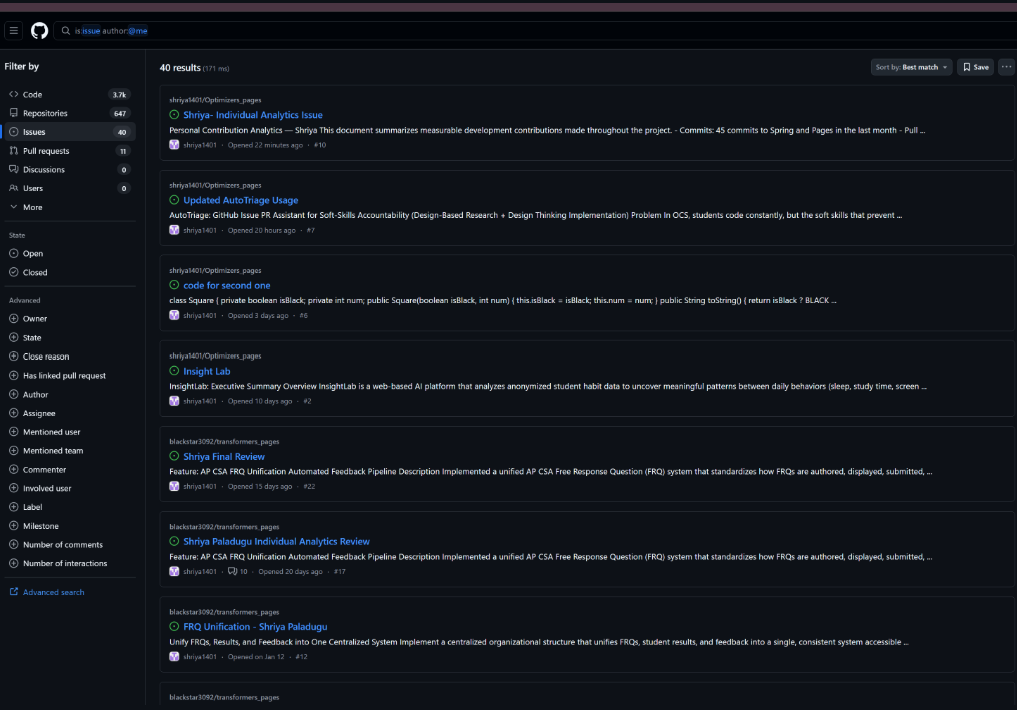
Issues: 32 issues created for planning and organization
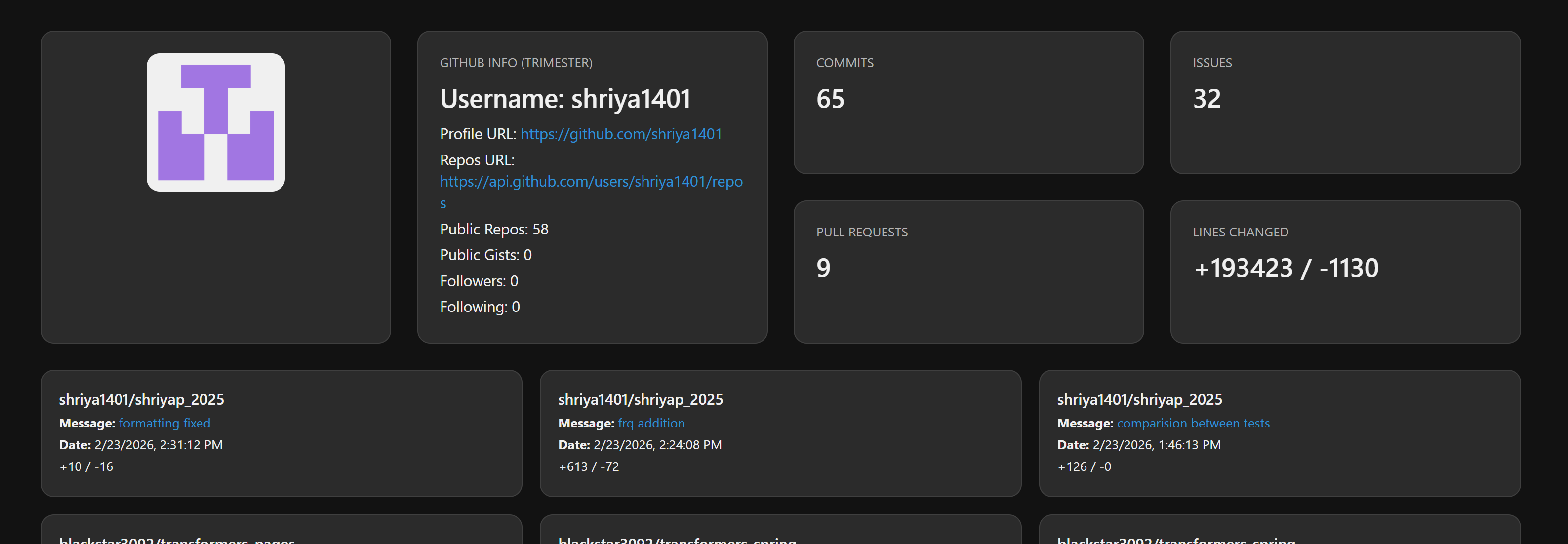
Issues
Records of created, managed, and resolved issues within the repository.
Commit Activity
Steady commit history reflecting ongoing development work across the project timeline.
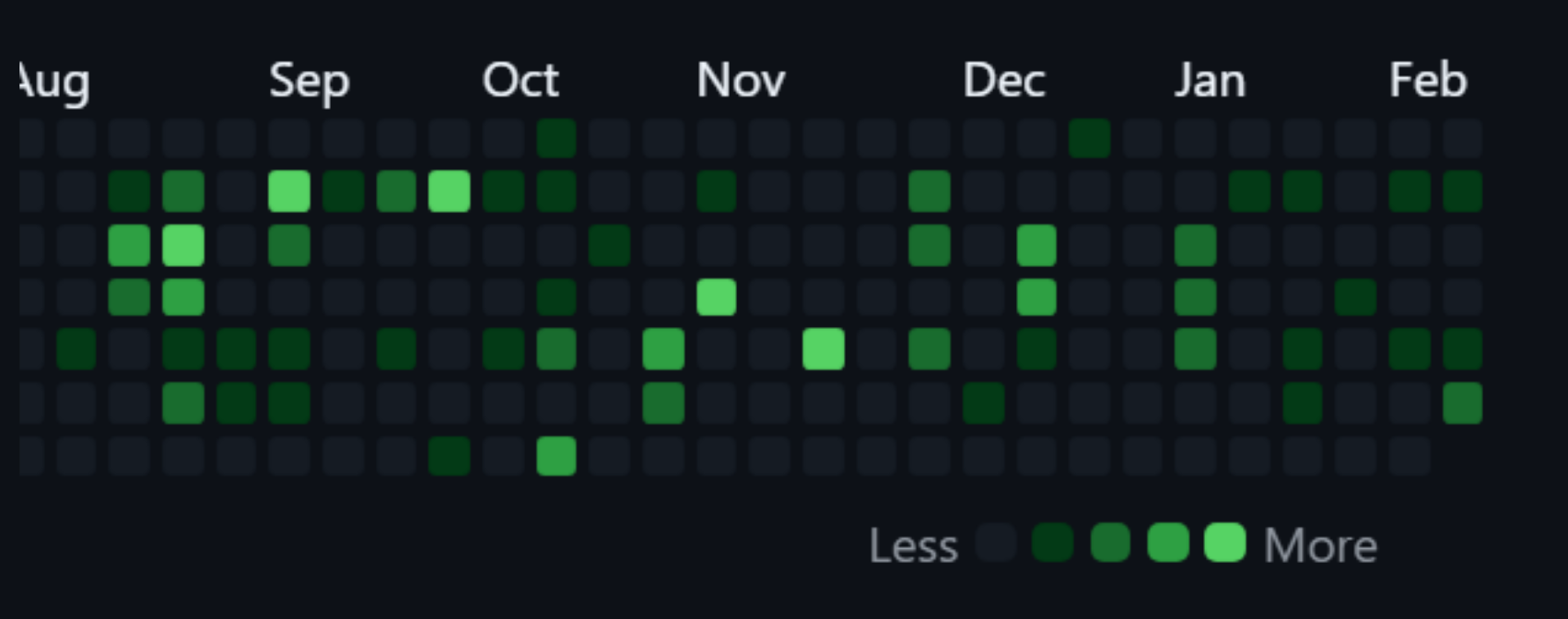
What this indicates
- Consistent engagement in coding tasks
- Continuous improvements rather than last-minute uploads
- Active participation throughout different phases of development
Pull Requests
Pull requests opened, reviewed, and successfully merged into the main branch.
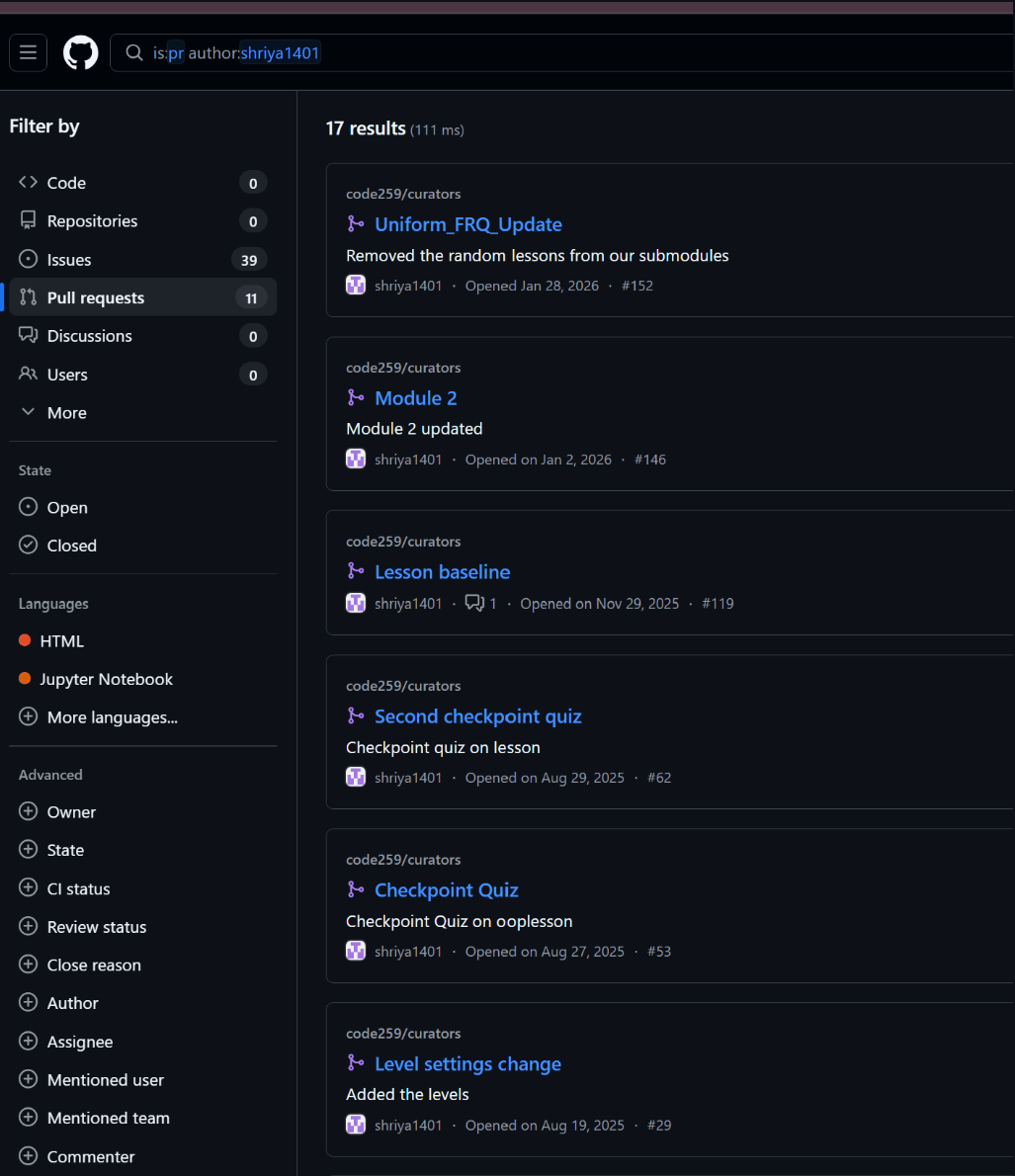
What this indicates
- Ownership of feature implementation
- Meaningful contributions to the shared codebase
- Collaboration through structured review and merge workflows
Contributions to Pages
Documented updates and commits related to project documentation or GitHub Pages.
What this indicates
- Sustained involvement in project progress
- Ongoing responsibility in development and maintenance
Overall Summary
These analytics highlight consistent technical contribution, collaborative engagement, and accountability throughout the coding, reviewing, and planning stages of the project lifecycle.
Dynamic Rate Limiting — Adaptive API Protection in Spring Boot
Overview
This trimester, I implemented a dynamic rate limiting system in the Spring Boot backend to protect APIs from abuse while maintaining fairness and scalability under varying load conditions.
Rather than using a static per-user request limit, I designed a system that:
- Tracks active authenticated users
- Dynamically adjusts request limits based on system load
- Rebuilds user-specific token buckets when limits change
- Uses Bucket4j for in-memory token bucket enforcement
- Prevents abuse while scaling gracefully
The result is an adaptive rate limiter that balances protection and performance.
Part 1 — The Problem
APIs are vulnerable to:
- Brute-force login attempts
- API scraping
- Automated abuse
- Resource exhaustion under high load
A static rate limit (e.g., 20 requests per minute) has drawbacks:
- Too restrictive when few users are active
- Too permissive during high traffic
- Does not scale with system load
We needed a smarter system that adjusts limits dynamically.
Part 2 — The Solution
I implemented a RateLimitFilter using Spring’s OncePerRequestFilter and Bucket4j.
@Component
public class RateLimitFilter extends OncePerRequestFilter {
This filter:
- Executes once per HTTP request
- Identifies the user (or IP if unauthenticated)
- Computes a dynamic rate limit
- Applies token bucket enforcement
- Returns HTTP 429 when the limit is exceeded
Part 3 — Core Design
1. User Identification
Each request is mapped to a unique key:
String username = request.getUserPrincipal() != null
? request.getUserPrincipal().getName()
: request.getRemoteAddr();
This ensures:
- Authenticated users are rate limited individually
- Unauthenticated users are rate limited by IP
2. Active User Tracking
Authenticated users are tracked:
if (request.getUserPrincipal() != null) {
activeUsers.put(username, true);
}
This allows the system to compute limits based on real-time user load.
3. Dynamic Limit Calculation
Instead of a fixed limit, the system adjusts based on active users:
private int computeDynamicLimit(String username, int activeUsers) {
if (activeUsers < 5) {
return 100;
} else if (activeUsers < 20) {
return 300;
} else {
return 600;
}
}
Logic Breakdown
| Active Users | Requests Per Minute |
|---|---|
| < 5 | 100 |
| < 20 | 300 |
| 20+ | 600 |
This ensures:
- Generous limits when few users are online
- Higher aggregate throughput when system usage grows
- Adaptive scaling behavior
Part 4 — Token Bucket Implementation (Bucket4j)
Each user has their own bucket stored in a concurrent cache:
private final Map<String, Bucket> cache = new ConcurrentHashMap<>();
private final Map<String, Integer> userLimits = new ConcurrentHashMap<>();
When a limit changes, the bucket is rebuilt:
cache.put(username, createBucketWithLimit(dynamicLimit));
userLimits.put(username, dynamicLimit);
Bucket Creation
private Bucket createBucketWithLimit(int limit) {
Bandwidth bandwidth = Bandwidth.builder()
.capacity(limit)
.refillGreedy(limit, Duration.ofMinutes(1))
.build();
return Bucket.builder()
.addLimit(bandwidth)
.build();
}
How This Works
capacity(limit)→ Maximum tokens availablerefillGreedy(limit, Duration.ofMinutes(1))→ Refill all tokens every minutetryConsume(1)→ Consumes 1 token per request
If no tokens remain, the request is rejected.
Part 5 — Request Flow
For every request:
- Identify user or IP
- Track active authenticated users
- Compute dynamic limit
- Rebuild bucket if limit changed
- Attempt to consume 1 token
- If allowed → continue request
- If denied → return HTTP 429
if (bucket.tryConsume(1)) {
filterChain.doFilter(request, response);
} else {
response.setStatus(429);
response.getWriter().write("Too many requests - limit: " + dynamicLimit + " per minute");
}
Part 6 — Why This Design Works
Thread-Safe
Uses ConcurrentHashMap for safe concurrent access.
Per-User Isolation
Each user/IP has their own independent bucket.
Dynamic Adaptation
Limits adjust automatically as user load changes.
Minimal Overhead
In-memory token buckets are lightweight and fast.
Configurable Defaults
Default limit can be injected via:
@Value("${security.rate-limit.requests-per-minute:20}")
This allows environment-based configuration.
Part 7 — Security Impact
This rate limiter protects against:
- Brute force attacks
- API scraping
- Request flooding
- Denial-of-service style abuse
And it does so without punishing legitimate users during low-traffic periods.
Future Improvements
Near-Term
- Add sliding window tracking instead of greedy refill
- Track burst detection patterns
- Add logging for rate-limit violations
- Include
Retry-Afterheader
Longer-Term
- Redis-backed distributed rate limiting
- Separate limits per endpoint
- Role-based rate limits (admin vs student)
- Integration with anomaly detection system
- Dashboard for monitoring rate-limit metrics
Reflection
This project reinforced an important engineering principle:
Security controls should scale with system behavior.
A fixed rate limit is simple, but adaptive rate limiting is resilient.
By combining:
- Spring Security
- Bucket4j token buckets
- Real-time active user tracking
I built a rate limiting system that protects APIs while preserving flexibility.
It is not just a throttle — it is an adaptive protection layer.
FRQ Unification : Standardizing AP CSA Free Response Across the Platform
Overview
This trimester, my work focused on eliminating fragmentation in how AP CSA Free Response Questions (FRQs) were authored, displayed, submitted, graded, and reviewed across the Open Coding Society platform.
Previously, FRQs were implemented as question-specific features. Each year or problem often had custom frontend layouts and inconsistent backend submission logic. This slowed development, created duplication, and made automation difficult.
The solution was to design and implement a fully unified FRQ system built around:
- One reusable frontend layout
- A centralized backend submission pipeline
- Automated AI rubric grading
- Structured, persistent feedback storage
- Seamless integration with existing assignment and grading systems
This transformed FRQs from isolated pages into a standardized, extensible framework.
Part 1 — FRQ Fragmentation
The Problem
FRQs were previously implemented with:
- Question-specific layouts
- Hardcoded rendering logic
- Inconsistent submission handling
- Disconnected grading workflows
Adding a new FRQ required touching multiple frontend and backend files.
This created:
- Duplicate layout code
- Increased maintenance cost
- Risk of inconsistent student experience
- Difficulty integrating AI grading cleanly
The system lacked a single source of truth for FRQs.
The Fix — Unified FRQ Layout
I introduced a single reusable layout:
_layouts/frq.html
All FRQs now can use metadata-driven front matter:
---
layout: frq
title: 2025 FRQ 2
year: 2025
frq_number: 2
unit: Arrays
category: Methods and Control Flow
---
The layout dynamically renders:
- Question metadata
- Prompt content
- Submission textarea
- Submission + refresh logic
Why This Works
- No hardcoded question IDs
- No duplicated layout logic
- All FRQs share the same rendering engine
- Adding new FRQs requires only metadata
This shifted FRQs from “custom pages” to structured content.
Part 2 — Unified Submission & Grading Pipeline
The Problem
Before unification:
- Submission handling varied across FRQs
- Grading logic was not centralized
- AI feedback lacked consistent structure
- Submissions were not fully aligned with assignment systems
This prevented clean automation.
The Fix — Centralized Submission Flow
All FRQs now can follow a single submission pipeline.
Step 1 — Save Submission
POST /api/submissions/submit/{assignmentId}
Creates a new AssignmentSubmission record.

Step 2 — Trigger AI Grading
POST /api/frq-feedback/submission/{submissionId}
This:
- Sends student response to Gemini
- Applies AP-style rubric evaluation
- Generates structured feedback
- Persists results to database
Step 3 — Retrieve Updated Results
GET /api/submissions/getSubmissions/{studentId}
Allows frontend to refresh and display:
- Score
- Strengths
- Improvements
- Overall comments
Authentication
All requests use:
credentials: "include"
This ensures:
- Session-based authentication
- No hardcoded student IDs
- Secure mapping between users and submissions
Part 3 — Structured Feedback & Persistence
The Problem
AI grading output must be:
- Structured
- Persistable
- Queryable
- Transparent
- Future-proof
Storing raw text responses would limit analytics and extensibility.
The Fix — Structured Feedback Object
Feedback is stored in a normalized format inside the feedback table.
assignment_submission Table
Stores:
- Student response
- Normalized numeric score
- Feedback summary
- Timestamps
This acts as the canonical grading record.
feedback Table
Stores:
- Score breakdown
- Strengths
- Areas for improvement
- Overall feedback
- Raw AI response
- Grading metadata
Example Feedback Payload
{
"question_id": "2025-FRQ-2",
"score": 7,
"max_score": 9,
"strengths": [
"Correct use of instance variables",
"Clear method structure"
],
"improvements": [
"Missing edge-case handling",
"Loop condition could be simplified"
],
"overall_feedback": "Strong implementation with minor logical gaps.",
"graded_at": "2026-01-24T10:12:00Z",
"graded_by": "Gemini AI"
}
Why This Matters
- Enables cross-FRQ analytics
- Supports rubric adjustments without schema churn
- Allows dashboards and exports
- Improves transparency for students
- Preserves raw output for debugging
Integration With Existing Systems
A core principle was unification, not duplication.
The FRQ system integrates directly with:
1. AssignmentSubmission Framework
FRQs are treated as standard assignments.
This enables:
- Individual grading
- Group submissions
- Grade back-propagation
- Dashboard integration
No special-case logic required.
2. Grade API
Because FRQs persist as AssignmentSubmission records:
- Scores appear in grade dashboards
- Exports work automatically
- Analytics remain consistent
3. Gemini AI Feedback Service
The unified layout connects directly to the Gemini grading service.
The end-to-end flow:
Frontend → Submission API → Gemini → Structured Feedback → Persistence → Display
This ensures consistency across all FRQs.
Relevant PRs & Commits
| Commit / PR | Description |
|---|---|
aa304e6 |
Create unified FRQ layout |
5d73750 |
Integrate FRQ with AssignmentSubmission system |
| ` 8286e24` | Connect Gemini grading pipeline |
c68416e |
Normalize structured feedback storage |
Impact & Benefits
Consistency
All FRQs now can follow a single rendering and grading workflow.
Scalability
Supports all AP CSA FRQs across years using one layout.
New FRQs require:
- Front matter metadata
- Prompt content
No backend changes.
Automation
Manual grading is replaced with rubric-aligned AI evaluation.
Maintainability
Fragmented code paths eliminated. Future enhancements require changes in one place.
Future Improvements
Near-Term
- Rubric calibration improvements
- AI confidence scoring
- Cross-FRQ performance analytics
- Response similarity detection
Longer-Term
- Instructor override interface
- Rubric version tracking
- Comparative cohort analytics
- AI drift monitoring
- Real-time grading performance dashboards
Reflection
The biggest lesson this trimester was that fragmentation quietly compounds technical debt.
The database reliability project taught me that reactive systems fail under pressure.
The FRQ Unification project reinforced that proactive system design prevents fragmentation before it spreads.
By consolidating FRQs into a single reusable pipeline:
- Developer velocity increased
- Student experience became consistent
- AI grading became reliable
- Maintenance complexity dropped
What was previously a collection of isolated features is now a standardized grading framework.
Instead of building individual FRQs, we built an infrastructure.
And infrastructure scales.
Computer Science Growth : Before vs After the Trimester
Overview
This trimester marked a major shift in how I approach computer science. The change wasn’t about working harder — I was already putting in significant effort — but about working with more structure, focus, and long-term system awareness.
Before the Trimester
I was already highly productive and deeply involved in development. I built complex backend features, worked across multiple repositories, implemented new functionality quickly, and handled bugs and integration issues independently. I consistently pushed commits and contributed to architecture discussions — comfortable jumping into new challenges and moving fast.
However, my workflow often looked like this: build Feature A, notice an improvement opportunity in Feature B, switch to Feature B, start Feature C, return to Feature A later. I was doing a lot and learning rapidly, but sometimes splitting attention across multiple parallel improvements.
My mindset was: “Keep building. Keep improving. Keep moving.”
That energy was a strength — but it needed refinement.
After the Trimester
This trimester helped me refine that energy into discipline. Working on larger systems like FRQ Unification, database recovery and migration pipelines, dynamic rate limiting, and automated database protection required sustained focus and architectural consistency.
Now I design features fully before implementing, finish one feature end-to-end before moving on, prioritize integration and testing earlier, think about long-term maintenance while coding, and build reusable infrastructure instead of isolated features.
Instead of simply asking “What can I improve next?” I now ask “What is the most strategically important thing to complete right now?”
What Actually Changed
1. Focus Shift — From Parallel to Sequential Depth
Before, I worked on multiple improvements simultaneously. Now I complete features with full lifecycle discipline: Design → Implement → Test → Integrate → Document → Move On. The workload stayed high — but the execution became more deliberate.
2. From Feature Builder to System Thinker
Before, I was strong at implementing functionality quickly. Now I’m strong at designing systems that unify and scale. Converting fragmented FRQs into a unified grading framework, designing adaptive rate limiting instead of static throttling, and building automated recovery pipelines instead of manual fixes — the shift wasn’t about capability, it was about architectural maturity.
3. From Reactive Improvement to Proactive Design
Before: see problem → fix problem. Now: anticipate problem → design protection → automate resilience. This trimester strengthened my ability to think several layers ahead — what breaks under scale, what happens under failure, how does this integrate long-term, can this be reused instead of rewritten?
Biggest Growth
I didn’t become more hardworking — I became more intentional. I moved from a high-output developer to a high-output systems designer. The energy and drive were always there. What improved was focus, sequencing, and architectural depth.
Final Reflection
This trimester refined how I build.
I was already building a lot. Now I build with structure. I was already solving problems. Now I design systems that prevent them.
The growth wasn’t in effort — it was in engineering maturity. And that shift has elevated both the quality and impact of my work.